

robots协议是什么?
robots是一个协议,是建立在网站根目录下的一个以(robots.txt)结尾的文本文件,对搜索引擎蜘蛛的一种限制指令。
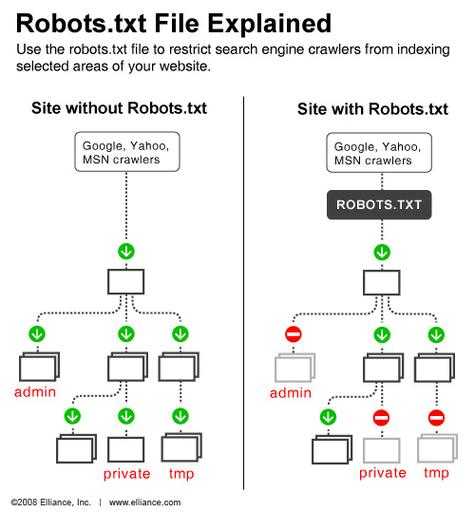
简单来说即:robots协议是一个君子协议,是网站所有者编写的,用来告诉搜索引擎该网站下的哪些内容可以爬取、收录,哪些内容不可以爬取和收录。
Robots协议是一种用于网站管理者通知网络爬虫哪些页面可以被爬取的协议。通过在网站的根目录下放置一个名为robots.txt的文件,网站管理者可以指定哪些页面可以被爬取,哪些页面不可以被爬取。
新建的网站,这个robots是什么意思?
1、网站开放给所有搜索引擎爬虫抓取(User-agent:*)禁止所有爬虫程序抓取根目录下的caches目录(Disallow:/caches)新站收录本身没有那么快,可尝试加入百度站长平台,利用官方工具提交网站Sitemap文件。
2、搜索引擎爬去我们页面的工具叫做搜索引擎机器人,也生动的叫做“蜘蛛”蜘蛛在爬去网站页面之前,会先去访问网站根目录下面的一个文件,就是robots.txt。
3、Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(RobotsExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
4、robots是英语中的一个词汇,意思是“机器人(们)”。
5、Robots协议通常被称为是爬虫协议、机器人协议,主要是在搜素引擎中会见到,其本质是网站和搜索引擎爬虫的沟通方式,用来指导搜索引擎更好地抓取网站内容,而不是作为搜索引擎之间互相限制和不正当竞争的工具。
6、原因:百度无法抓取网站,因为其robots.txt文件屏蔽了百度。方法:修改robots文件并取消对该页面的阻止。机器人的标准写法详见百度百科:网页链接。更新百度站长平台(更名为百度资源平台)上的网站机器人。
robots协议
1、Robots是一个英文单词,对英语比较懂的朋友相信都知道,Robots的中文意思是机器人。而我们通常提到的主要是Robots协议,这也是搜索引擎的国际默认公约。
2、对的。Robots协议是一种用于网站管理者通知网络爬虫哪些页面可以被爬取的协议。通过在网站的根目录下放置一个名为robots.txt的文件,网站管理者可以指定哪些页面可以被爬取,哪些页面不可以被爬取。
3、方法一: 通过输入网址“https://”,进入百度搜索引擎页面。
4、Robots简单来说就是搜索引擎和我们网站之间的一个协议,用于定义搜索引擎抓取和禁止的协议。
5、接下来以亚马逊的robots协议为例,分析其内容。首先,先来分析亚马逊对于网络爬虫的限制。是否有有“特殊权限”的爬虫?爬虫抓取时会声明自己的身份,这就是User-agent,就是http协议里的User-agent。
6、Robots协议的本质是网站和搜索引擎爬虫的沟通方式,是用来指引搜索引擎更好地抓取网站里的内容。比如说,一个搜索蜘蛛访问一个网站时,它第一个首先检查的文件就是该网站的根目录里有没有robots.txt文件。

 61040202000743
61040202000743